
Моя статья набрала 70 000 просмотров на Хабре. Вторую — отклонили, обвинив в ИИ-генерации. Вот она целиком — судите сами.
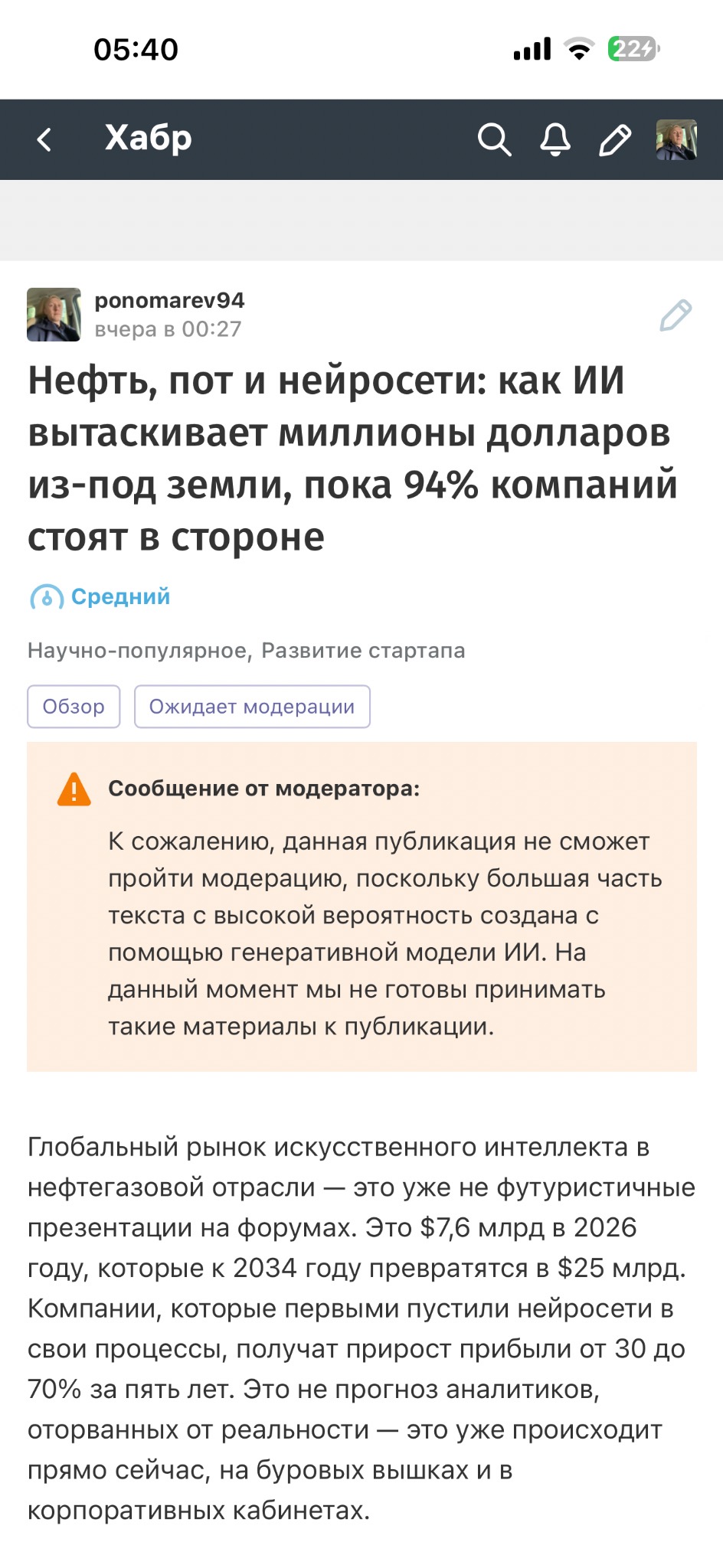
26 апреля 2026 года я получил сообщение, от которого у меня дёрнулся глаз. Модератор Хабра написал: «К сожалению, данная публикация не сможет пройти модерацию, поскольку большая часть текста с высокой вероятность создана с помощью генеративной модели ИИ. На данный момент мы не готовы принимать такие материалы к публикации».
Я — Андрей Пономарев, эксперт по искусственному интеллекту и промпт-инжинирингу, автор книг и десятков публикаций, в шаге от защиты кандидатской диссертации по геолого-минералогическим наукам. Моя первая статья на Хабре набрала более 70 000 просмотров. Я написал вторую статью — большой аналитический материал об ИИ в нефтегазовой отрасли — по теме, в которой разбираюсь профессионально. Написал сам. Руками. Головой. С опорой на реальные данные, кейсы и многолетний опыт работы с нефтегазовыми компаниями.
И мне сказали, что это написала нейросеть.
Что произошло
Я подготовил статью «Нефть, пот и нейросети: как ИИ вытаскивает миллионы долларов из-под земли, пока 94% компаний стоят в стороне». Тема — прикладное использование искусственного интеллекта в нефтегазовой отрасли: мировые кейсы BP, Shell, ADNOC, Baker Hughes и российский опыт «Газпром нефти», «Роснефти», «Татнефти», «ЛУКОЙЛа». Материал основан на открытых отчётах, исследованиях Boston Consulting Group, Deloitte, McKinsey и Accenture, а также на моём личном опыте внедрения ИИ в реальный бизнес.
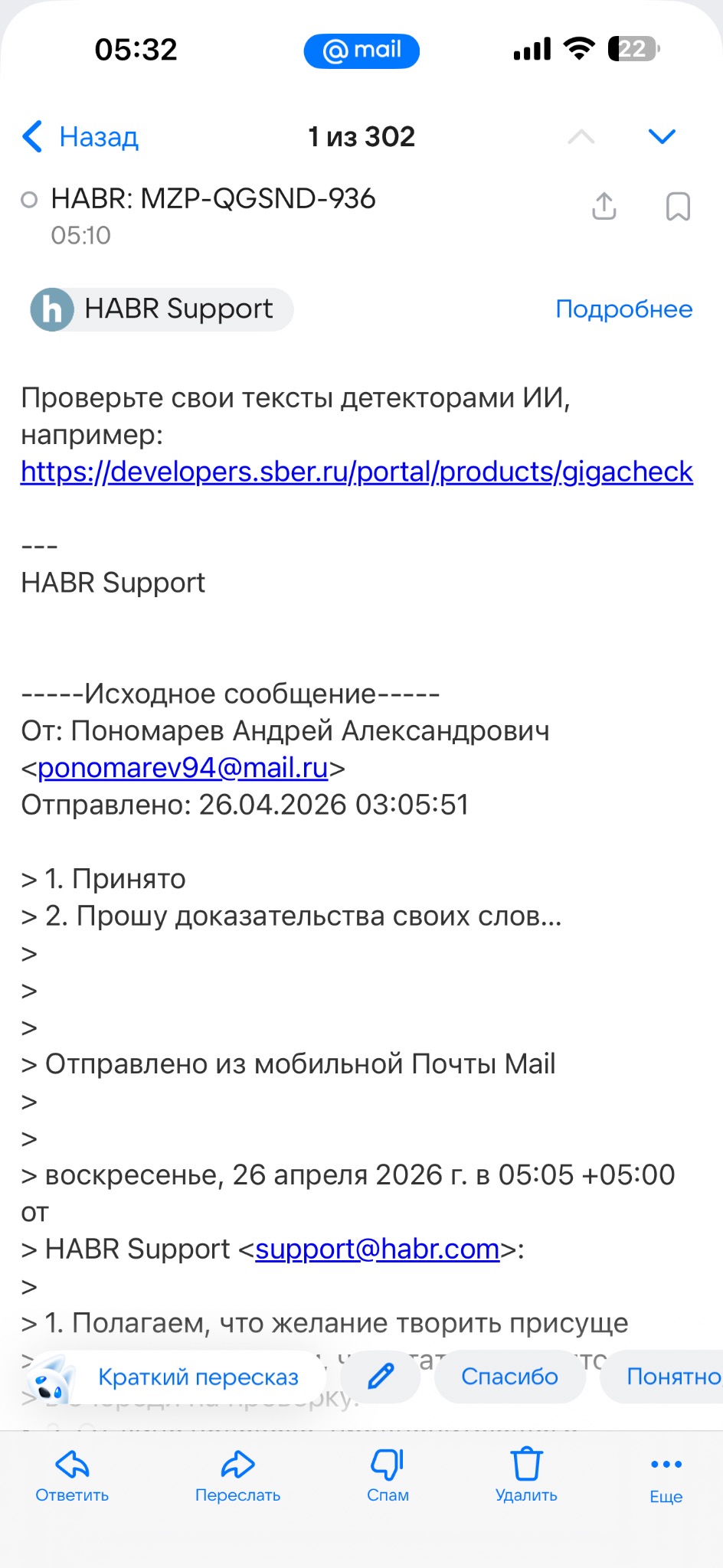
Хабр отклонил публикацию. Я переработал текст и отправил повторно. Хабр снова отклонил. В переписке с поддержкой мне предложили «проверить свои тексты детекторами ИИ» и дали ссылку на GigaCheck от Сбера.
Я проверил. GigaCheck вынес вердикт: «Текст, скорее всего, написан генеративной моделью ИИ».
Мой текст. Написанный мной. Человеком. Экспертом с десятками публикаций, диссертацией на подходе и реальным опытом в отрасли.
Почему это абсурд
Давайте разберёмся, что такое GigaCheck. Это детектор ИИ-текстов от Сбера, который на конференции GigaConf 2024 заявил о точности 94,7%. Звучит внушительно — пока не начинаешь копать.
Независимых исследований точности GigaCheck не существует. Зато существует статья на vc.ru, автор которой протестировал 10 текстов — и GigaCheck ошибся в 3 случаях из 10. Тридцать процентов ошибок. Каждый третий текст определён неверно. И на основании этого инструмента крупнейшая IT-площадка Рунета решает, публиковать ли экспертный материал или нет.
Обратите внимание на формулировку: «скорее всего». Не «точно», не «однозначно» — «скорее всего». Это сознательная размытость, которая позволяет сервису снять с себя ответственность за ложные срабатывания. Но модераторы Хабра воспринимают этот вероятностный вердикт как окончательный приговор.
Проблема не уникальна для GigaCheck. Мировые исследования показывают системный кризис AI-детекторов. GPTZero в ходе тестирования пометил 7 из 10 человеческих текстов как ИИ-генерированные. ZeroGPT в одном из исследований определил 83% текстов, написанных людьми, как синтетические. Turnitin — крупнейший мировой сервис проверки академических работ — публично признал проблему ложных срабатываний. В апреле 2026 года конференция ICLR отклонила 497 научных работ по подозрению в ИИ-генерации рецензий.
Ни одного детектора, способного со стопроцентной вероятностью определить происхождение текста, не существует. Это не моё мнение — это консенсус исследовательского сообщества.
Что это значит для авторов
Ситуация, в которой я оказался, касается не только меня. Она касается каждого, кто пишет качественные экспертные тексты в 2026 году.
Парадокс в следующем: чем лучше вы пишете, тем выше вероятность, что алгоритм примет ваш текст за машинный. Структурированная аргументация, грамотный язык, логичное изложение — всё это «подозрительные признаки» для детектора, который обучен на паттернах языковых моделей. Получается, что единственный способ пройти проверку — писать хуже. Вставлять ошибки. Ломать логику. Делать текст «человечнее» в понимании алгоритма, то есть — хуже.
Это не просто техническая проблема. Это удар по самому принципу экспертного контента. Площадки, которые должны поддерживать качественные публикации, начинают отсеивать их на основании инструментов с доказанно высоким процентом ошибок.
Я готов защищать свои тексты. Я могу предоставить черновики, историю правок, источники данных, экспертные комментарии. Но мне даже не дали такой возможности. Вместо диалога — ссылка на GigaCheck.
Статья, которую Хабр не опубликовал
Ниже — полный текст статьи, которую Хабр отклонил. Прочитайте её и решите сами: это текст, написанный нейросетью, или экспертный аналитический материал, основанный на реальных данных и глубоком понимании отрасли?
Нефть, пот и нейросети: как ИИ вытаскивает миллионы долларов из-под земли, пока 94% компаний стоят в стороне
Глобальный рынок искусственного интеллекта в нефтегазовой отрасли — это уже не футуристичные презентации на форумах. Это $7,6 млрд в 2026 году, которые к 2034 году превратятся в $25 млрд. Компании, которые первыми пустили нейросети в свои процессы, получат прирост прибыли от 30 до 70% за пять лет. Это не прогноз аналитиков, оторванных от реальности — это уже происходит прямо сейчас, на буровых вышках и в корпоративных кабинетах.
Нефтегазовая отрасль исторически была одной из самых консервативных в мире. Десятилетиями здесь полагались на мозолистый опыт бурильщиков, интуицию геологов, передаваемую из поколения в поколение, и бесконечные, неповоротливые таблицы Excel. Но в 2025-2026 годах произошёл тектонический сдвиг. Искусственный интеллект сбросил с себя ярлык «экспериментальной игрушки» и превратился в суровый производственный инструмент — эдакого цифрового прораба, который ежедневно принимает решения ценой в миллионы долларов.
В этой статье мы разберем лучшие мировые кейсы применения ИИ в нефтегазе — от автономного бурения, где алгоритмы заменяют месяцы человеческого труда, до генеративных копайлотов, спасающих инженеров от бумажной рутины. Мы посмотрим, как эти технологии приживаются в суровых российских реалиях на примерах «Газпром нефти», «Роснефти», «Татнефти» и «ЛУКОЙЛа». Все процессы мы разделим на два контура: внешний (операционный — это «мускулы» компании) и внутренний (корпоративный — её «мозг»).
Часть 1. Внешний контур: цифровые двойники и умные скважины
Внешний контур — это непосредственно «поле»: геологоразведка, проектирование бурения, оптимизация добычи и транспортировка углеводородов. Здесь цена ошибки измеряется не выговором от начальства, а миллионами долларов убытков и экологическими катастрофами. Именно поэтому ИИ во внешнем контуре даёт самый ощутимый, осязаемый экономический эффект.
Мировой опыт: когда алгоритмы видят сквозь землю
Мировые лидеры уже перешагнули этап робких пилотных проектов и перешли к полномасштабному промышленному внедрению ИИ. Согласно исследованию Boston Consulting Group, компании, максимально использующие ИИ на всех этапах добычи, могут увеличить свою прибыль (EBIT) на 30-70% в течение следующих пяти лет. Это не абстрактная цифра — она подтверждается конкретными кейсами.
Британская BP разработала инструмент под названием «Optimization Genie». Эта нейросеть в реальном времени вгрызается в данные с датчиков глубоководных платформ в Мексиканском заливе. Алгоритм непрерывно, словно опытный дирижер, корректирует параметры добычи — давление, температуру, скорость потока — и находит оптимальные режимы работы. Результат ошеломляет: дополнительные 2000 баррелей нефтяного эквивалента в день только на одном кластере скважин. В масштабах года это десятки миллионов долларов дополнительной выручки, добытой буквально из воздуха.
Но BP пошла еще дальше, создавая цифровые двойники своих офшорных платформ. С помощью лазерного сканирования и машинного обучения инженеры получают виртуальную копию платформы. На ней можно моделировать ремонтные работы, планировать логистику и обучать персонал — всё это без необходимости отправлять людей в открытое штормовое море. Как выразился один из инженеров BP: «Раньше для планирования замены насоса нужно было лететь на вертолёте. Теперь я делаю это с ноутбука в Хьюстоне».
Shell использует высокопроизводительные вычисления и ИИ для определения оптимальных траекторий бурения. Традиционно этот процесс напоминал блуждание в лабиринте и занимал месяцы работы команды геологов и инженеров. Теперь алгоритмы перебирают тысячи вариантов и находят наиболее рентабельные маршруты за считанные дни. Кроме того, внедрение предиктивного обслуживания на основе машинного обучения позволило Shell сократить незапланированные простои оборудования на 15-20%. Для компании с тысячами единиц оборудования по всему миру это колоссальная экономия.
Национальная нефтяная компания Абу-Даби (ADNOC) действует еще агрессивнее. В 2023 году компания сгенерировала $500 млн дополнительной стоимости благодаря развёртыванию более 30 ИИ-инструментов. Эти решения охватывают весь цикл: от интерпретации сейсмических данных до оптимизации логистики танкерного флота. Отдельно стоит отметить экологический эффект: ИИ-системы ADNOC помогли предотвратить выброс до 1 миллиона тонн CO₂, что делает компанию одним из лидеров «зелёной» цифровизации.
Baker Hughes развернула платформу Leucipa на тысячах скважин компании Expand Energy. Leucipa — это система автоматизированного управления месторождением на базе ИИ, которая самостоятельно принимает решения об оптимальных режимах работы скважин. Ключевой тренд здесь — переход к Agentic AI (агентному ИИ), когда система не просто рекомендует, а действует автономно, словно невидимый оператор.
Символичный момент произошел в марте 2026 года: Chevron заключила сделку на $7 млрд с Microsoft и Engine No.1 по энергоснабжению дата-центров для ИИ-вычислений. Нефтегазовые компании не только используют ИИ, но и становятся поставщиками энергии для самой ИИ-индустрии, замыкая круг.
Адаптация для России: суровые условия и цифровой прорыв
Российская нефтегазовая отрасль имеет свою специфику, которая одновременно возводит барьеры и открывает уникальные возможности для ИИ. Огромные расстояния, экстремальный климат Арктики и Западной Сибири, стареющая инфраструктура на зрелых месторождениях и курс на импортозамещение ПО — всё это формирует особый, жесткий контекст внедрения.
В апреле 2026 года «Газпром нефть» представила прорывную разработку — ИИ-агента для проектирования нефтяных скважин. Нейросеть способна генерировать до 1000 вариантов расстановки скважин за один час, анализируя миллионы параметров: геологические особенности пласта, экономику проекта, экологические ограничения. Для сравнения: команда инженеров тратит на аналогичную работу недели. Это не замена человека — это экзоскелет для мозга, который расширяет пространство решений на порядки.
Параллельно компания развивает «Цифровой двойник сейсморазведки» — систему, объединяющую данные по более чем 800 геологическим объектам, накопленные с 1999 года. ИИ анализирует эти данные, выявляя закономерности, которые человек просто физически не способен увидеть в таком океане информации.
«Роснефть» реализует масштабный проект «Цифровое месторождение», в рамках которого ИИ применяется для анализа данных сейсморазведки и оптимизации поиска углеводородов. Система «Цифровой геолог» существенно сокращает сроки анализа геологических данных, что критически важно при работе на новых участках в Восточной Сибири и на арктическом шельфе.
С 2022 года «ЛУКОЙЛ» использует нейросетевой модуль «Управление разработкой зрелых месторождений». Система оптимизирует режимы закачки воды на месторождениях Пермского края, где традиционные методы уже выдохлись и не дают прироста добычи. Это особенно актуально для России, где значительная часть месторождений находится на поздней стадии разработки и требует нестандартных, ювелирных подходов.
Часть 2. Внутренний контур: копайлоты и управление знаниями
Внутренний контур — это корпоративное управление, аналитика, документооборот, HR и логистика. Если внешний контур — это «мускулы» компании, то внутренний — её «мозг». И именно здесь генеративный ИИ совершает настоящую, тихую революцию.
Главный тренд 2025-2026 годов во внутреннем контуре — переход от простых чат-ботов и рекомендательных систем к Agentic AI (агентному ИИ). Это системы, которые способны не только отвечать на вопросы, но и самостоятельно выполнять цепочки задач: собирать данные из разных источников, формировать отчёты, инициировать закупки и даже координировать работу подрядчиков.
Крупнейшие нефтегазовые компании внедряют специализированные большие языковые модели (LLM), обученные на внутренней документации: регламентах, чертежах, истории ремонтов, геологических отчётах. Инженер на буровой может задать вопрос голосом — «Какой момент затяжки для фланца DN150 на линии высокого давления?» — и получить точный ответ за секунды, вместо того чтобы листать тысячестраничные руководства. В нештатной ситуации, когда счет идет на секунды, это может спасти жизни.
Подразделение bpx energy (onshore-бизнес BP) пилотирует использование генеративного ИИ для создания «утренних отчётов». Каждое утро нейросеть автоматически собирает данные за прошедшие сутки со всех скважин, анализирует отклонения от нормы и формирует краткий отчёт с ключевыми инсайтами для руководства. То, на что раньше уходило 2-3 часа работы аналитика, теперь делается за минуты, пока закипает кофе.
Отдельное направление — использование ИИ для прогнозирования цен на нефть и газ. Алгоритмы анализируют сотни факторов: от геополитических новостей до погодных условий и загрузки танкерного флота. По данным McKinsey, ИИ-трейдинг может увеличить маржу на торговых операциях на 10-15%.
В России внутренний контур ИИ имеет особое значение. Отрасль сталкивается с массовым уходом на пенсию опытных специалистов, а молодые кадры не всегда готовы работать в суровых условиях Крайнего Севера. ИИ-системы управления знаниями позволяют «оцифровать» опыт ветеранов и сделать его доступным для новых сотрудников.
Совместно с Университетом ИТМО «Татнефть» разработала платформу на основе больших языковых моделей. Система не просто отвечает на вопросы — она выступает как полноценный спарринг-партнер, помогая проводить мозговые штурмы, генерировать гипотезы и принимать стратегические решения. Платформа обучена на внутренних данных компании и глубоко понимает специфику нефтедобычи в Татарстане.
Одна из главных проблем внедрения ИИ — не технологии, а люди. «Газпром нефть» системно решает эту проблему: более 1600 сотрудников прошли обучение прогрессивной работе с ИИ. В условиях импортозамещения российские компании активно переходят на отечественные языковые модели для создания корпоративных баз знаний, что позволяет хранить чувствительные данные внутри страны.
Часть 3. Барьеры, перспективы и почему 94% компаний всё ещё ждут
Несмотря на впечатляющие кейсы, массовое внедрение ИИ в российском нефтегазе сталкивается с серьёзными препятствиями.
Исторические данные часто хранятся в разных форматах, на разных платформах, а иногда — просто пылятся на бумаге. Старые паспорта скважин, рукописные журналы бурения, разрозненные базы данных — всё это создаёт «цифровой хаос». По оценкам экспертов, до 60% времени Data Science-команд в нефтегазе уходит на банальную уборку — подготовку и очистку данных.
Кроме того, месторождения в Арктике, на Ямале и в Восточной Сибири часто не имеют стабильного интернет-соединения. Передача терабайтов данных с датчиков в облако — нетривиальная задача. Решение кроется в edge computing (вычислениях на границе сети), когда ИИ-модели работают непосредственно на промысловом оборудовании. Добавляет проблем и острый кадровый голод — нехватка специалистов, которые одновременно понимают Data Science и специфику нефтегаза.
Несмотря на эти барьеры, перспективы внушают оптимизм. По оценкам Минэнерго РФ, суммарный экономический эффект от внедрения ИИ в нефтегазовой отрасли за период с 2025 по 2040 годы может составить 5,4 трлн рублей. Консалтинговая компания «Выгон Консалтинг» оценивает ежегодный эффект от генеративного ИИ в 343 млрд рублей.
Но почему же тогда большинство компаний стоят в стороне? Как я отметил ранее в другой статье: «Я занимаюсь внедрением ИИ в реальный бизнес — от нефтегазовых компаний до розничных сетей — и вижу эту картину изнутри. Проблема не в технологиях. Технологии доступны, модели мощные, инструменты дешевеют с каждым месяцем. Проблема — в подходе. Компании начинают с технологии, а не с задачи. "Давайте внедрим GPT-4" — это не стратегия. Стратегия — это "давайте сократим время обработки заявок с 48 до 4 часов". Технология — лишь инструмент».
По данным Forbes, лишь 5,8% российских компаний реально используют искусственный интеллект в своих бизнес-процессах. Остальные 94% — наблюдают, экспериментируют или просто не понимают, с какой стороны подойти.
Глобальные исследования подтверждают этот тренд. По данным Deloitte, AI и генеративный ИИ сейчас составляют менее 20% IT-расходов нефтегазовых компаний США, но к 2029 году эта цифра превысит 50%. Ранние внедренцы уже сообщают о снижении отказов оборудования на 40% и экономии $10 млн в год. Accenture прогнозирует, что расходы энергетического сектора на генеративный ИИ вырастут в 3,5 раза к 2030 году, переопределив 44% всех рабочих задач в отрасли.
Искусственный интеллект в нефтегазовой отрасли — это уже не вопрос «внедрять или нет». Это вопрос выживания. Мировые мейджоры и российские лидеры уже показали, что ИИ способен генерировать сотни миллионов долларов дополнительной стоимости. Гонка началась, и те, кто останется на старте, рискуют навсегда остаться в аналоговом прошлом.
Послесловие
Вот эта статья. Прочитайте её ещё раз. Посмотрите на конкретные цифры, названия компаний, описания технологий, ссылки на исследования. Это не «сгенерированный контент». Это результат работы человека, который годами занимается внедрением ИИ в реальные отрасли.
Проблема AI-детекторов — это не техническая мелочь. Это системный сбой, который бьёт по экспертному сообществу. Когда площадки доверяют алгоритму с 30% ошибок больше, чем автору с доказанной экспертизой, — что-то пошло не так.
Я не против проверок. Я против слепого доверия инструментам, которые не способны отличить эксперта от нейросети. И я против системы, в которой автору не дают даже возможности доказать авторство.
Эта статья — моё доказательство. Судите сами.
Андрей Пономарев — эксперт по ИИ и промпт-инжинирингу, автор книг и десятков публикаций на Хабре, vc.ru и в научных журналах. Если вам нужна консультация по внедрению ИИ в бизнес — свяжитесь со мной.